浏览器渲染原理
大约 3 分钟约 886 字
浏览器渲染主要是依靠浏览器内核也就是浏览器渲染引擎,它通过一系列的解析将 HTML 文档渲染在浏览器上。
主要流程
渲染引擎会从网络层中获取将要渲染的文档,主要的工作流程如下:
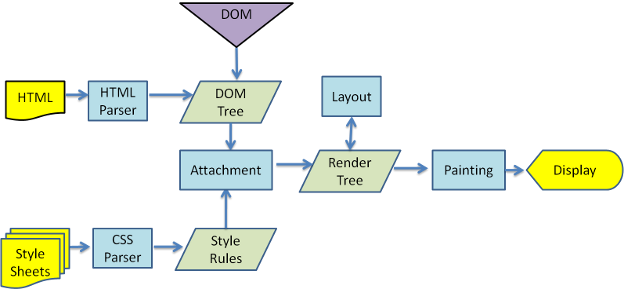
- 首先浏览器会解析 HTML 文档,将 HTML 解析成 DOM 树;CSS 样式表也会在同时进行加载,生成样式规则;而 JavaScript 会通过 DOM API 和 CSSOM API 来操作 DOM Tree 和 Style Rules。
- 解析完成后,渲染引擎会通过 DOM Tree 和 Style Rules 创造 Render Tree,此时会计算各个 DOM 在浏览器上的具体坐标。
- 最后渲染引擎遍历整个 Render Tree,由 UI 后端层绘制。
整个渲染过程一个渐进的过程。为了更好的用户体验,渲染引擎将尽快在屏幕上显示内容。在开始构件和渲染 Render Tree 之前,它不会等到所有 HTML 都被解析。在部分内容被渲染的同时,渲染引擎会继续向服务器请求剩下的内容。
HTML 解析器
HTML 解析器的作用是将 HTML 解析成 DOM 树:
<html>
<body>
<p>Hello World</p>
<div><img src="example.png" /></div>
</body>
</html>
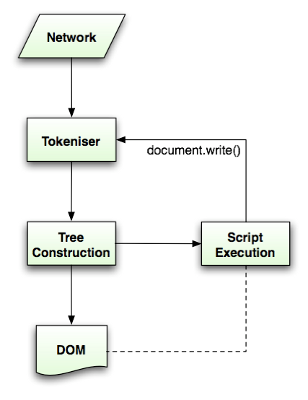
HTML 解析算法包括两个阶段:
- 标记化:词法分析,将输入解析为标记。HTML 标记包括开始标记、结束标记、属性名称和属性值。标记器识别 token,将它传递给树构造器,然后接受下一个字符以识别下一个标记,直到输入的结束。
- 树构建:构建成 DOM 树。
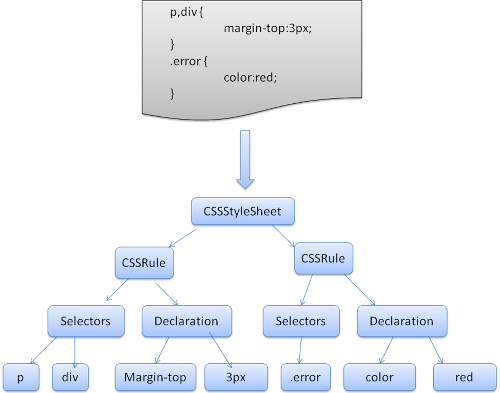
CSS 解析器
解析器都会将 CSS 文件解析成 StyleSheet 对象,且每个对象都包含 CSS 规则。CSS 规则对象则包含选择器和声明对象,以及其他与 CSS 语法对应的对象。
Render Tree
在 DOM 树构建的同时,浏览器还会构建另一个树结构:呈现树。这是由可视化元素按照其显示顺序而组成的树,也是文档的可视化表示。它的作用是让您按照正确的顺序绘制内容。
Render Tree 和 DOM Tree 并不是一一对应的,非可视化的 DOM 元素不会插入呈现树中,例如 head 元素。如果元素的 display 属性值为 none,那么也不会显示在呈现树中(但是 visibility 属性值为 hidden 的元素仍会显示)。
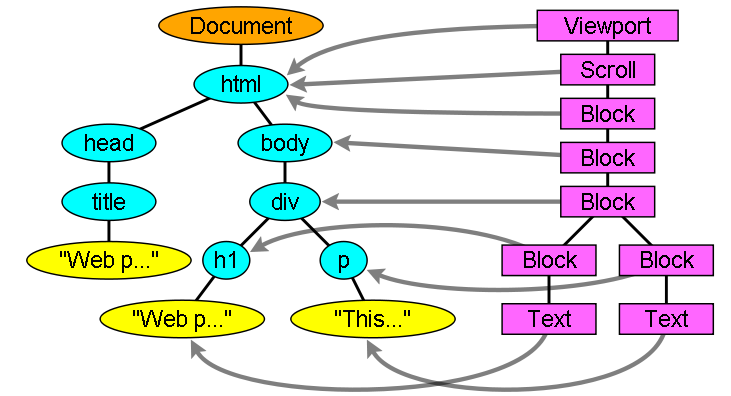
接下来浏览器需要做的就是计算样式,将每一个 Render 对象的可视化属性计算(根据一系列规则,如层叠性、选择器权重等)出来,但是在这个过程中,并不包含位置和大小信息。计算这些值的过程叫做布局或回流。
总之,到目前为止,渲染引擎已经经历了一系列的工作,可以将页面展示到浏览器上了。