V8 引擎
在 JavaScript 引擎中,V8 无疑是最流行的,Chrome 与 Node.js 都使用了 V8 引擎。
V8 由很多子模块构成,有几个核心模块:
- Parser:解析器,负责将 JavaScript 代码解析成抽象语法树(Abstract Syntax Tree, AST);
- Ignition:解释器(interpreter),负责将 AST 转换为字节码(Bytecode)并执行;同时收集 TurboFan 优化编译所需的信息,比如函数参数的类型;
- TurboFan:编译器(compiler),利用 Ignition 所收集的信息,将字节码转换为优化的机器码;
- Orinoco:垃圾回收(garbage collector),负责将程序不再需要的内存空间回收。
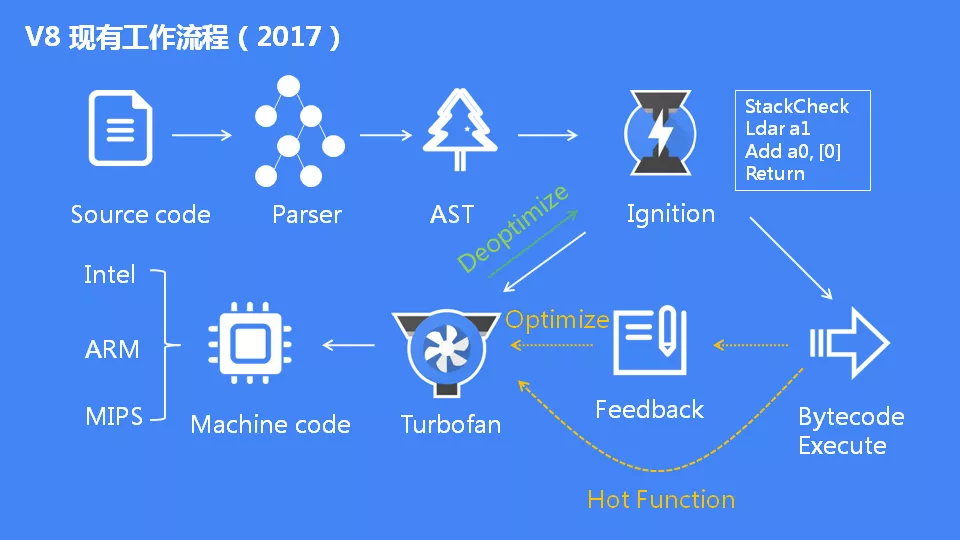
下面这张图是 V8 现有的工作流程,非常重要,在后面阅读的时候可以翻上来看看。
Parser
为了让 V8 能够理解 JavaScript 代码,必须先将源码通过 Parser 解析成抽象语法树——代表程序结构的一系列对象。然后抽象语法树会被 Ignition 编译成字节码。这两个阶段是 V8 引擎性能的关键。
下图是 Parser 的工作流程:

整个流程分为两个阶段:词法分析和语法分析。
- 词法分析:scanner 从我们编写的 JavaScript 代码中生成一系列的 tokens。而 tokens 是由一个或多个具有单一语义的字符组成的块:字符串、标识符、运算符
++等。 - 语法分析:语法分析的输入就是词法分析的输出(即 tokens),输出是 AST 抽象语法树。当程序出现语法错误的时候,V8 会在语法分析阶段抛出异常。
V8 为了提升 scanner 性能,又做了 延迟解析(lazy parsing)的优化,一些不会用到函数并不会被马上编译,他们会被 PreParser 处理,当以后调用一个 preparsed 函数时,它会根据需要进行完全解析和编译。
Ignition
当 Parser 将代码解析成 AST 输入给 Ignition,Ignition 会将 AST 转换为字节码,分三种情况:
- 函数只声明而不调用,则 Ignition 不会做任何操作;
- 如果函数只调用一次,则 Ignition 会解释字节码并执行。下面来看看例子;
- 如果函数调用多次,则 Ignition 会收集 TurboFan 优化所需的信息(比如函数参数的类型信息等)。
下面来看看例子。
只是声明函数
add,但是没有调用,则 Ignition 不会做任何转换。function add(x, y) { return x + y }声明后第一次调用
add函数,Ignition 会把它编译成字节码执行。到这个时候,JavaScript 代码就已经执行完成了。add(1 + 1)但是如果发现有热点函数(即一个函数被多次调用),Ignition 就会收集
add函数的各种参数类型,为 TurboFan 的优化提供支持。// 调用多次,标记成热点函数,收集各种信息 add(1 + 2) add(1 + 3)
TurboFan
TurboFan 是一个编译器,可以将字节码编译为 CPU 可以直接执行的机器码。如果一个函数被多次调用,就会被标记为热点函数,那么就会经过 TurboFan 转换成优化的机器码,提高代码的执行性能。
function add(x, y) {
return x + y
}
add(1, 1) % OptimizeFunctionOnNextCall(add)
add(1, 2)
V8 的 %OptimizeFunctionOnNextCall 可以直接指定优化哪个函数,它根据上次调用的参数反馈优化 add 函数,很明显这次的反馈是整型数,所以 TurboFan 会根据参数是整型数进行优化直接生成机器码,下次函数调用直接调用优化好的机器码。
但是,机器码实际上也会被还原为字节码,这是因为如果后续执行函数的过程中,类型发生了变化(比如 add 函数原来执行的是 number 类型,后来执行变成了 string 类型),之前优化的机器码并不能正确的处理运算,就会逆向的转换成字节码。这个就是最上面那个图还有个 Deoptimization 的原因。
function add(x, y) {
return x + y
}
add(1, 1)
add('1', '2')
到此,V8 引擎的工作流程就已经完成了,但是还没有细究里面的执行细节,只是大概地了解了工作流程,等以后能完全看懂官方文章了再回来更新。